Documentation depth
14 technical chapters
Complete thesis structure with methods, controls, and acceptance criteria.
Research Thesis
This document is written as a technical-first research thesis for clinicians, engineering teams, regulatory reviewers, and quality stakeholders. It describes the scientific rationale, sensing pipeline, quality-control doctrine, model governance, validation strategy, risk case, and claim boundaries that govern NoDraw. The framing is ambitious at the access layer and conservative at the clinical claim layer: scale early detection access while preserving explicit uncertainty and confirmatory-care requirements.
Documentation depth
14 technical chapters
Complete thesis structure with methods, controls, and acceptance criteria.
Evidence posture
Inline-cited
Claims are bound to references and release governance artifacts.
Safety doctrine
Pass / Reacquire / Abstain
Outputs are withheld whenever certainty or quality is insufficient.
Claim boundary
Early risk signals
Not a standalone replacement for clinician diagnosis or treatment pathways.
Version: v1.0-thesis
Last reviewed: February 15, 2026
Evidence cadence: Quarterly baseline; immediate update on evidence-tier or safety-policy changes.
Boundary notice
In plain language: Read this path first if you want the core science, limits, and safety logic without reading all 14 chapters in one pass.
What this page proves
What this page does not claim
In plain language: this section shows what is strongest today, where evidence is still developing, and which source supports each claim.
NoDraw is designed for conservative early risk signals with explicit abstain behavior instead of forced output.
Pass/reacquire/abstain controls are implemented before inference to prevent low-integrity captures from being interpreted.
Every release claim must map to a claim-evidence row with thresholds, owners, and boundary language.
Risk acceptance is continuously reassessed using drift signals, incident patterns, and change classes.
Feasibility, analytical validation, and clinical performance are separated to avoid metric over-interpretation.
Clear boundary language and explainable outputs reduce unsafe self-interpretation by end users.
In plain language: use this matrix to separate current supported behavior from emerging evidence and explicit non-claims.
| Status | What it means | Current position | Reader action |
|---|---|---|---|
| Supported now | Backed by defined controls and mapped evidence artifacts. | Capture gating, abstain policy, claim boundaries. | Use as baseline understanding of current product posture. |
| Emerging evidence | Methods and controls are defined, but broader validation expansion is in progress. | Subgroup scaling, external-site robustness, update-class thresholds. | Review chapter open questions before drawing deployment conclusions. |
| Not claimed | Explicitly out of scope or prohibited until evidence posture changes. | Autonomous final diagnosis, universal lab-equivalence claims. | Treat as non-deployable narrative until formal claim map changes. |
In plain language: this is the exact system flow from capture to either output or abstain.
Guided capture
User follows camera guidance for stable ocular acquisition.
If capture is unstable, move to reacquire instructions.
Quality control
QC scores lighting, focus, motion, and signal integrity.
If threshold fails, output is withheld and recapture is required.
Feature extraction
Validated preprocessing transforms are applied with versioned controls.
Transformation mismatches trigger conservative handling and logging.
Model ensemble
Endpoint models produce calibrated probabilities with uncertainty context.
Conflicting or low-confidence behavior triggers arbiter constraints.
Rules + ML arbiter
Deterministic policy rules gate what can be shown and how.
Boundary violations force abstain and escalation messaging.
Abstain or output
User receives either constrained risk signal guidance or explicit abstain notice.
No uncertain output is shown without passing policy requirements.
Interface Evidence
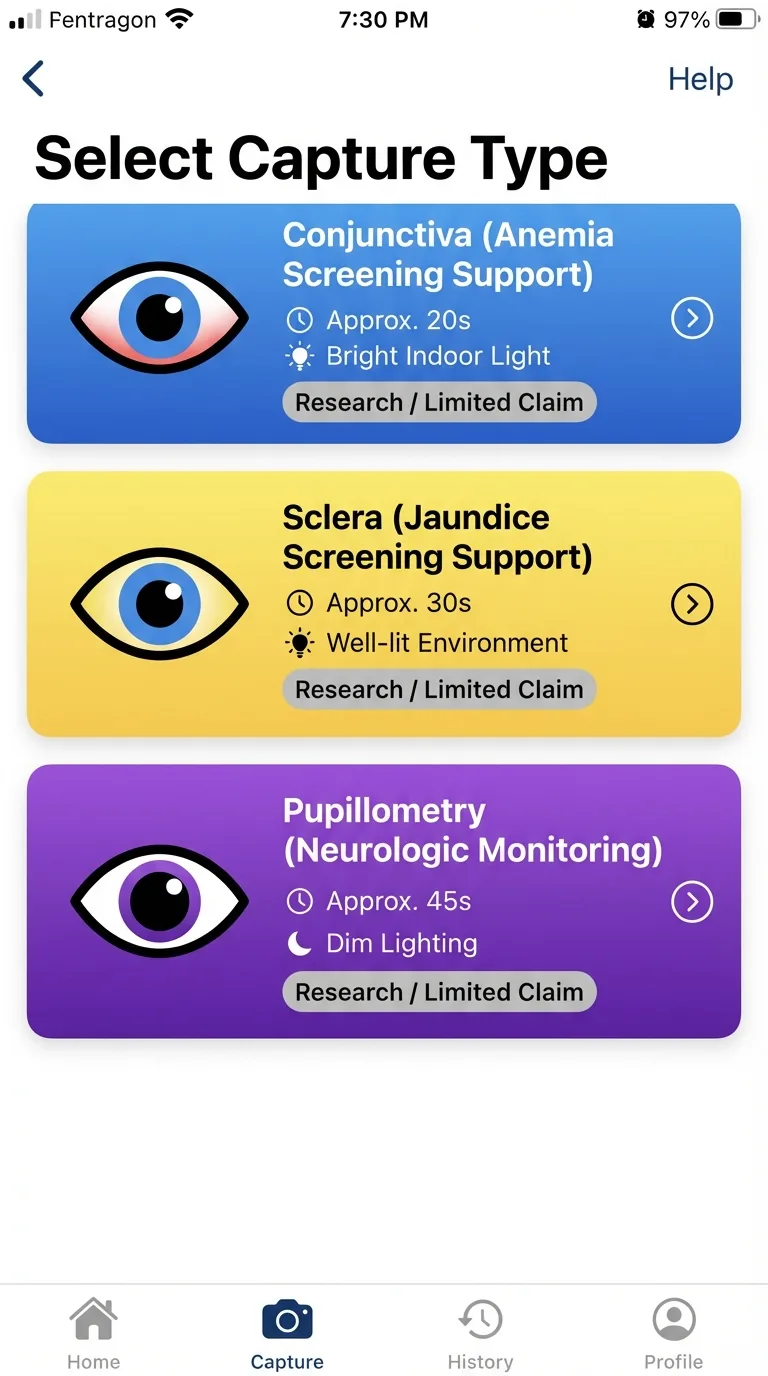
These product interfaces illustrate the operational workflow discussed in this thesis: mode selection, quality-gated capture, and role-aware routing.
Select capture type
Choose the right capture path for the biomarker context.

Quality gate HUD
Real-time quality checks gate results and trigger recapture when needed.
Role-aware routing
Different users enter role-specific, privacy-aware workflows.
These are interface illustrations of workflow behavior; validation claims are established in cited study sections.
In plain language: the system is designed for early risk signals and mandatory follow-up routing, not autonomous diagnosis.
Use the complete chapter sequence for architecture, regulatory, validation, risk, and operations depth.
Chapter jump
Chapter 01
NoDraw is presented as a phone-scale diagnostic access thesis: transform smartphone camera signals into quality-gated early risk outputs while preserving strict medical safety boundaries, explicit uncertainty handling, and confirmatory-care routing.
Why this chapter exists
Reader question: What is NoDraw claiming, and what is it not claiming?
Without clear thesis boundaries, readers cannot distinguish strategic vision from release-safe clinical positioning.
Estimated reading time: 7 min
The central thesis is that a smartphone-only ocular biomarker stack can become clinically useful when engineered as a constrained safety system rather than a generic prediction engine. The product promise is intentionally ambitious at the access layer and intentionally conservative at the claim layer: increase screening reach, reduce startup friction, and accelerate triage without claiming definitive diagnosis autonomy. This dual stance is the core design doctrine of the program.
From an evidence perspective, this thesis only holds if each output is mediated by measurable quality controls, reproducible acquisition constraints, and calibrated confidence logic. The practical implication is that the app must be designed to abstain frequently in adverse conditions rather than fabricate certainty. Program value is therefore determined by both what it predicts and what it refuses to predict.
Visionary framing with controlled claims
NoDraw is framed as infrastructure for earlier detection access at population scale. It is not framed as a replacement for clinician-led diagnosis or laboratory confirmation.
Program thesis pillars
Quantitative anchor
Utility = Access Gain x (Clinical Signal Quality) x (Safety Compliance)Program utility is treated as a multiplicative relationship: failures in safety compliance or signal quality collapse practical value regardless of access scale.
| Dimension | Target posture | Operational implication |
|---|---|---|
| Clinical positioning | Early risk signal system | No definitive standalone diagnosis claim |
| Form factor | Smartphone-only | No external optical attachment or specimen kit required |
| Safety behavior | Pass / Reacquire / Abstain | Output withheld when signal quality or certainty is insufficient |
| Deployment model | Request-first with confirmatory routing | No treatment decision automation without clinician confirmation |
Program positioning and release doctrine
Figure: Program thesis and safety doctrine
mermaid
flowchart LR
Vision[Visionary phone-scale access] --> Gate[Quality gate doctrine]
Gate --> Output[Early risk signals]
Output --> Confirm[Confirmatory clinical pathway]High-level doctrine: visionary research framing with conservative medical safety boundaries.
The thesis explicitly assumes that the greatest near-term clinical value of phone-only diagnostics lies in earlier risk visibility rather than endpoint finality. In low-friction screening contexts, the system can reduce the delay between subjective symptom onset and objective triage action, particularly where laboratory access windows are narrow or operationally expensive. This value proposition requires discipline: scale cannot be used to justify lower evidence thresholds. Instead, scale is treated as the multiplier that makes strict safety controls more important, not less important, because any defect in interpretation can propagate rapidly across large populations.
Program leadership is framed around three parallel obligations: scientific coherence, operational control, and communication fidelity. Scientific coherence means feature-to-label logic must remain explainable and testable. Operational control means model and rule changes are release-governed rather than opportunistic. Communication fidelity means public statements must remain synchronized with measurable evidence posture. When one of these obligations drifts, the program enters a reputational and safety debt state. This chapter therefore treats executive language as a technical artifact, because framing errors at the top of the stack often become hidden defects in downstream product behavior and policy decisions.
A notable design principle in this thesis is that abstain behavior is interpreted as a quality success signal, not a conversion failure. In classical consumer UX, withholding output is viewed as friction; in medical software, withholding uncertain output is the ethical center of the product. This redefinition requires both interface and operations alignment: users need understandable abstain messaging, support teams need escalation scripts, and analytics teams need abstain telemetry by device cohort. If abstain behavior is suppressed to improve vanity metrics, the system drifts toward unsafe confidence and breaks the foundational thesis.
The executive scope also commits to longitudinal accountability. A thesis-grade product cannot rely on launch-time evidence alone; it must continuously validate that real-world populations, software updates, and camera pipeline drift have not invalidated prior claims. For this reason, chapter-level acceptance criteria are intentionally operational and version-aware. Each claim is considered provisional until reinforced by post-market stability evidence. This posture preserves ambition while acknowledging epistemic limits in dynamic mobile ecosystems where hardware and firmware conditions can change faster than traditional clinical evidence cycles.
Executive accountability is also expanded around measurable thesis health indicators. The program should track evidence freshness, boundary adherence, abstain appropriateness, and escalation completion quality as leadership metrics, not only conversion or acquisition growth. This avoids a common digital health distortion where business dashboards silently reward aggressive output behavior while safety controls degrade. By defining leadership KPIs that include conservative operating behavior, the executive layer can protect technical teams from short-horizon pressure that would otherwise undermine risk posture. This chapter therefore positions executive governance as the first control surface for responsible scaling.
The thesis further commits to decision transparency across internal and external stakeholders. When model behavior changes, reviewers should be able to identify what changed, why it changed, how it was validated, and which claims were affected. This principle reduces ambiguity during release review and during external scrutiny from clinical partners. It also creates a durable institutional memory, so decisions remain understandable even when teams evolve. In practice, executive clarity is expressed through versioned claim maps, chapter-level acceptance gates, and auditable change logs that keep strategic ambition aligned with verifiable evidence.
This chapter is expanded as a deeper methodological narrative around executive thesis governance and strategic safety alignment. The thesis assumes that durable clinical utility emerges only when early-risk signal doctrine and abstain-first safety logic is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how cross-functional claim governance and leadership KPI design should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of strategic overclaim pressure and metric misalignment. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on evidence freshness, boundary compliance, and traceable decision history. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. This chapter's integrity determines whether users encounter trustworthy guidance or confidence-inflated narratives is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
NoDraw outputs early risk signals only; treatment decisions require clinician confirmation and appropriate reference testing.
Acceptance criteria
Key takeaway
NoDraw is framed as an early-risk signal platform with explicit abstain and confirmatory-care doctrine.
Open questions
Chapter 02
This chapter translates existing AstraCBC corpus documents into an implementation-ready gap closure map: what is already specified, what is underspecified, and what evidence artifacts must be generated to support thesis-grade publication and release governance.
Why this chapter exists
Reader question: Which evidence gaps are still material before claims can be trusted?
Readers need to see not just what is written, but where evidence is incomplete or governance is unresolved.
Estimated reading time: 8 min
The internal corpus already defines a robust skeleton: phone-only architecture, quality gates, arbitration logic, risk register intent, and validation trajectory. What it lacks in the product-facing research page is depth of representation. The route currently summarizes outcomes but does not expose assumptions, formulas, benchmark design, or artifact-level traceability needed by technical reviewers.
A gap-first approach is used here because credibility failure in medical software usually arises from omission rather than commission: missing dataset governance, missing subgroup criteria, missing claim boundaries, and missing operational thresholds. The redesign therefore treats documentation as an executable governance layer. If a claim cannot be traced to evidence fields, the claim is considered non-deployable.
Gap closure method
Quantitative anchor
Claim Readiness Score = (Evidence Completeness x Traceability x Reproducibility) / Open Critical GapsA practical heuristic for whether a claim can graduate from concept narrative to externally defensible technical communication.
| Gap class | Observed state | Required closure action |
|---|---|---|
| Dataset disclosure | No public structured dataset card | Publish capture protocol, cohort strata, exclusion criteria |
| Quantitative outputs | No performance metrics in current route | Expose endpoint metrics table and confidence intervals |
| Claim-evidence traceability | Template exists but not rendered in product | Render claim-to-evidence map in research route |
| Operational safety evidence | Risk template present but not surfaced | Publish top hazards, controls, residual posture |
AstraCBC extract gap inventory translated to implementation work
Figure: Gap closure sequence
mermaid
flowchart TD
Gap[Source gap] --> Spec[Data/spec definition]
Spec --> Build[Renderer + evidence block]
Build --> Verify[Consistency and citation checks]
Verify --> Publish[Research chapter release]How source-document gaps translate into concrete productized evidence artifacts.
The extract process distinguishes between missing information and missing governance. Missing information refers to absent metrics, cohort definitions, or protocol specifics. Missing governance refers to unassigned ownership, unclear acceptance thresholds, or no change-control discipline. Both failure modes can independently invalidate claim credibility. A section may look complete narratively while still being non-operational if no owner can verify its assertions. The editorial pass therefore upgrades prose into accountable evidence language, where each statement can be traced to either an internal source artifact or an external framework requirement with a clear implementation consequence.
Gap closure is treated as an iterative systems process rather than a one-time documentation sprint. As chapters mature, new second-order gaps become visible: for example, a complete table may expose missing statistical assumptions, or a clear claim boundary may reveal unsupported UX phrasing elsewhere. The research page is therefore designed to behave like a living dossier. Version tagging, explicit review cadence, and chapter-level acceptance criteria create a mechanism to absorb new evidence and retire outdated assumptions without rewriting foundational doctrine each cycle.
Another key closure action is harmonizing terminology across product, clinical, and regulatory domains. Terms such as risk signal, confidence band, severity grade, and confirmatory path must mean the same thing in UX copy, validation reports, and governance templates. Terminology drift creates hidden ambiguity that can distort trial design, analytics interpretation, and legal review. This pass intentionally normalizes language at chapter level so downstream teams can reuse exact definitions. Controlled vocabulary is treated as a safety control because inconsistent terms frequently lead to inconsistent decisions in distributed programs.
Finally, gap closure includes publication integrity controls. Inline citations are not cosmetic; they force sentence-level accountability and reduce the risk of unsupported narrative escalation. By requiring citations on non-trivial assertions, the page becomes self-auditing: unsupported statements are immediately visible as citation gaps. This improves both internal review speed and external trust. In effect, the editorial system becomes part of the quality system, because documentation defects can be detected and corrected using the same traceability mindset applied to software defects.
A deeper extraction pass should explicitly separate definitional gaps, quantitative gaps, and governance gaps, because each requires different remediation. Definitional gaps are solved by controlled vocabulary and scope clarity. Quantitative gaps require study design, datasets, and metrics. Governance gaps require ownership, timelines, and release controls. Treating them as one generic backlog category obscures progress and creates false completion signals. This chapter now recommends a gap board keyed to evidence criticality: blocker gaps that prevent claim publication, structural gaps that slow review, and enhancement gaps that improve resilience but are not release blockers. That structure improves execution focus while preserving long-term quality.
The extraction process should also include contradiction checks across documents and UI copy. A frequent failure pattern is local correctness with global inconsistency: one chapter states conservative boundaries while another implies near-definitive behavior. Contradictions of this type are high-risk because they are difficult to detect in isolated review. By running systematic contradiction sweeps and linking outcomes to citation IDs, the research route becomes a coherence instrument rather than a content repository. The result is a tighter evidence narrative where reviewers can validate not only detail depth, but also consistency across all decision-critical surfaces.
This chapter is expanded as a deeper methodological narrative around gap taxonomy and source-to-claim traceability. The thesis assumes that durable clinical utility emerges only when assumption extraction and contradiction-resilient terminology control is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how closure workflows for definitional, quantitative, and governance gaps should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of silent omissions that appear complete but remain non-deployable. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on citation-bound sentence accountability and auditable closure status. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. When gap analysis is weak, users are exposed to promises that are not fully supported by evidence is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
Unmapped claims are treated as aspirational and are excluded from release-critical positioning.
Acceptance criteria
Key takeaway
Gap closure is a managed evidence workflow, not a one-time copy update.
Open questions
Chapter 03
Defines intended use, user cohorts, device assumptions, and hard non-claims for a smartphone-only ocular biomarker SaMD deployment profile.
Why this chapter exists
Reader question: Where does the phone-only system work reliably, and where must it abstain?
Scope drift is a major source of overclaim and misinterpretation in medical software products.
Estimated reading time: 8 min
NoDraw is scoped as a software-led triage system that transforms guided ocular capture into early risk labels with uncertainty metadata and escalation pathways. The intended role is decision support for access and triage, not autonomous diagnosis authority. This distinction is central to risk governance, communication strategy, and regulatory framing.
Scope includes smartphone camera acquisition, on-device quality gating, feature extraction, model inference, and rule-based arbitration. Scope excludes any requirement for attachment optics, consumable kits, or specimen collection. Scope also excludes unsupported claims such as universal device parity without qualification and definitive diagnosis without confirmatory evaluation.
Intended-use envelope
Non-claim constraints
The system does not claim direct blood cell counting from camera imagery, nor universal biomarker equivalence against laboratory methods across all contexts.
Quantitative anchor
Deployable Scope = Intended Use - {Unsupported Capture Modes, Unsupported Claims, Unsupported Devices}Scope control is treated as subtraction against failure-prone and non-validated domains.
| Domain | In scope | Out of scope | Reason |
|---|---|---|---|
| Capture region | Conjunctiva, sclera, pupil | Non-validated camera regions | Signal reproducibility and protocol maturity |
| Hardware | Native smartphone camera stack | External lens modules | Strict deployment simplicity and scale |
| Clinical output | Triage signal labels | Definitive treatment directives | Boundary safety and legal posture |
| Fundus without attachments | Research-only high-abstain | Routine production output | Geometry and optical constraints |
In-scope vs out-of-scope scope boundaries
Figure: Scope envelope
Depicts hard boundaries between validated ocular zones and excluded acquisition pathways.
Scope engineering is framed as a risk-reduction instrument, not a feature-limitation compromise. In practical terms, this means selecting clinically meaningful use cases where smartphone optics and protocol controls can produce reproducible input distributions. The thesis rejects broad but weakly substantiated scope expansion in favor of narrower domains with stronger evidence progression. This approach improves eventual scalability because validated scope can be expanded systematically, while over-broad scope typically produces unstable outputs that force reactive rollback and confidence erosion.
The user-facing product promise is intentionally split into two layers: diagnostic orientation and decision boundary. Diagnostic orientation tells users what the system can flag early. Decision boundary tells users what the system cannot finalize independently. Both are required for safe interpretation. If only orientation is shown, users overtrust outputs; if only boundary is shown, users ignore utility. Scope-complete communication therefore pairs capability statements with explicit limitations in the same context block, reducing the cognitive gap between signal receipt and follow-up action.
Device qualification is another core scope boundary. Smartphone-only does not imply device-agnostic parity. Camera pipeline differences can materially alter feature stability, so support matrices are treated as clinical controls rather than marketing constraints. Unsupported devices are not soft-failed; they are hard-gated to prevent unsafe inference under unknown pipeline conditions. This policy allows expansion over time through evidence-backed onboarding of additional device families. The chapter therefore treats compatibility management as part of the intended-use envelope and not a separate operations concern.
Scope also includes temporal boundaries. Outputs are context-bound to the capture episode and do not imply persistent diagnosis state without longitudinal evidence. Where longitudinal mode exists, it modifies confidence and urgency only through predefined rules, not heuristic trend storytelling. This temporal discipline matters because users may infer chronic conclusions from single-session outputs if boundaries are not explicit. The scope framework therefore includes not only what is measured and on which devices, but also when and for how long an interpretation is considered valid.
Scope expansion decisions should be managed through a staged readiness ladder. Stage one establishes physiological plausibility and protocol reliability for a narrow context. Stage two demonstrates analytical stability under device and demographic stratification. Stage three adds clinical utility evidence and operational readiness constraints. Only after all three are complete should scope be widened. This ladder prevents premature market statements and creates explicit criteria for when a use case transitions from exploratory to deployable. It also protects support and clinical teams from absorbing uncertainty that should have been resolved in pre-release evidence work.
An important editorial refinement is describing scope boundaries in user-operational terms, not only technical terms. Users and partners need to know when outputs are expected to be reliable, what capture contexts are unsupported, and what next step is required when uncertainty is high. Scope language should therefore bind engineering constraints to user actions: supported devices, minimum capture conditions, abstain behavior, and confirmatory routing. This makes scope enforcement legible and reduces the gap between internal validation logic and practical field behavior, which is essential for safe adoption in mixed-resource settings.
This chapter is expanded as a deeper methodological narrative around intended-use envelope design and exclusion governance. The thesis assumes that durable clinical utility emerges only when scope-limited physiological claims tied to validated capture contexts is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how device qualification, context gating, and enforceable non-claim behavior should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of scope creep that outpaces validation and destabilizes output reliability. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on readiness ladders linking exploratory hypotheses to deployable statements. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Scope discipline ensures users receive outputs matched to validated conditions instead of speculative interpretations is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
Any use case outside the validated scope envelope must default to abstain and referral guidance.
Acceptance criteria
Key takeaway
Deployable scope is tightly bounded by validated devices, contexts, and claim limitations.
Open questions
Chapter 04
Maps thesis claims to recognized standards and guidance frameworks required for a credible SaMD lifecycle.
Why this chapter exists
Reader question: How are scientific claims connected to formal quality and regulatory controls?
Evidence without controlled process execution is not enough for medical-grade software credibility.
Estimated reading time: 10 min
A thesis-grade research program must prove not only that outputs can be generated, but that those outputs are governed under a reproducible lifecycle model. For NoDraw, this means pairing evidence narrative with a standards-aligned quality operating system. IMDRF N41 frames evidence categories, ISO 13485 governs QMS mechanics, ISO 14971 governs risk posture, and IEC 62304 governs software controls.
Usability and safety are not post-processing tasks. IEC 62366-1 requirements are integrated directly into capture and escalation flows because most real-world harm in early-stage diagnostic software emerges from misunderstanding and misuse. Eye-directed lighting context is addressed through ISO 15004 and IEC 62471 references for risk framing and control boundaries.
Regulatory-grade AI operations additionally require controlled change mechanisms. FDA PCCP and cybersecurity guidance are used here as operational constraints: model updates must be pre-characterized, validated by change class, and deployed with monitoring and rollback controls. This chapter therefore treats documentation as part of runtime safety.
Artifact chain
Quantitative anchor
Regulatory Readiness = Evidence Quality + Process Compliance + Change Control DisciplineNo single domain can compensate for failure in another.
| Framework | Primary role | Core artifact |
|---|---|---|
| IMDRF N41 | SaMD clinical evaluation | Clinical Evaluation Plan and evidence chain |
| ISO 13485 | Quality management system | Design controls, CAPA, change control |
| ISO 14971 | Risk management | Hazard analysis and residual risk review |
| IEC 62304 | Software lifecycle | Software lifecycle plan, verification matrix |
| IEC 62366-1 | Usability engineering | Critical task analysis and summative report |
| ISO 15004 + IEC 62471 | Eye/light safety context | Illumination risk and exposure controls |
Regulatory and quality framework mapping
Figure: Regulatory traceability map
mermaid
flowchart LR
IMDRF --> CEP
ISO13485 --> QMS[QMS records]
ISO14971 --> RMF[Risk file]
IEC62304 --> SLP[Software lifecycle plan]
IEC62366 --> UE[Usability file]Framework-to-artifact mapping for review readiness.
A rigorous research route must make visible the bridge between scientific argument and controlled process execution. Regulatory frameworks are often cited abstractly; this chapter operationalizes them as concrete deliverables and decision checkpoints. For example, citing ISO 14971 without a maintained hazard-control map adds no real safety value. Likewise, citing IEC 62304 without release-classified verification evidence leaves software claims ungrounded. The editorial expansion therefore translates framework references into artifact obligations, ownership assignments, and review timing so compliance posture is inspectable rather than rhetorical.
The chapter also addresses sequencing across frameworks. QMS controls, risk controls, and software lifecycle controls are interdependent and should be staged coherently. A common failure mode is late-stage risk analysis after architecture choices are already fixed, which limits meaningful mitigation options. In this thesis, risk and usability signals are intended to influence architecture and protocol decisions early, before model and interface contracts harden. This sequencing reduces retrofit risk and supports cleaner traceability when external reviewers request rationale for major design decisions.
Controlled AI updates receive special treatment because model evolution is continuous while regulatory confidence depends on bounded change. The PCCP-inspired approach here defines update classes with associated validation burden and deployment constraints. Minor recalibration, feature pipeline updates, and endpoint logic changes are not treated equivalently. Each change class requires predefined test deltas, drift checks, and rollback preparedness before promotion. This chapter documents that logic so future model improvements can move faster without compromising evidentiary discipline or forcing ad hoc approval cycles.
Cross-jurisdiction privacy and security obligations are integrated into the same governance narrative. Clinical usefulness cannot be separated from lawful data handling and secure software operation. The thesis therefore links privacy doctrine, cybersecurity controls, and clinical governance rather than presenting them as separate compliance tracks. This integrated view matters operationally because incident response, auditability, and user trust often depend on coordinated handling across these domains. A mature SaMD posture requires that data governance decisions be as explicit and reviewable as inference and validation decisions.
A thesis-grade regulatory narrative should expose the complete design-control lineage: user need, design input, design output, verification, validation, and release decision rationale. When this lineage is visible, external reviewers can test whether evidence truly supports intended use. When hidden, compliance statements become difficult to trust even if underlying work exists. This chapter therefore emphasizes artifact architecture as much as standards references. The objective is not broad framework citation volume, but inspectable linkage from requirement to test evidence to residual risk acceptance.
QMS maturity is further defined by response quality under change and incident conditions. A compliant static state is insufficient for mobile software ecosystems where device firmware, camera behavior, and user patterns shift continuously. The program must demonstrate controlled adaptation: impact analysis, gated validation, decision logs, and post-release monitoring aligned to update class. By embedding this dynamic quality model in the chapter, NoDraw frames compliance as a continuous operating discipline, not a one-time documentation milestone prior to launch.
This chapter is expanded as a deeper methodological narrative around design-control lineage and standards-integrated quality operations. The thesis assumes that durable clinical utility emerges only when artifact-linked compliance translation from framework language to executable process is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how coordinated sequencing across QMS, risk, usability, and software lifecycle controls should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of documentation-heavy but action-light compliance postures. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on inspectable requirement-to-test-to-risk traceability under controlled change. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Strong quality governance improves consistency of safety behavior users experience across releases is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
If process compliance cannot be demonstrated, output performance claims are considered non-deployable.
Acceptance criteria
Key takeaway
Standards references must map to concrete, owned artifacts and release controls.
Open questions
Chapter 05
Defines the practical optical and ergonomic protocol needed for repeatable smartphone-only ocular acquisition.
Why this chapter exists
Reader question: How does NoDraw handle optical instability in real user environments?
Capture quality is upstream of all inference validity and is the first safety-critical system layer.
Estimated reading time: 10 min
Smartphone ocular capture is constrained by ambient variability, glare, motion, and heterogeneous ISP pipelines. Therefore capture quality is treated as a protocol problem first and an ML problem second. The UI must actively stabilize user behavior through framing guides, hold timers, and adaptive feedback rather than passively collecting arbitrary frames.
Ergonomic design has direct analytical consequences: head pose, blink timing, capture distance, and lighting angle materially change signal viability. The product strategy accepts this and encodes ergonomic controls into acquisition flow. In this model, UX design is part of the sensing stack and should be validated with the same rigor as model components.
Capture protocol controls
Quantitative anchor
Capture Quality Index = w1*focus + w2*stability + w3*exposure + w4*(1-glare)Composite quality index used to determine pass or reacquire behavior.
| Control point | Specification target | Failure response |
|---|---|---|
| Frame hold window | 3-5 seconds stable window | Prompt hold-still recapture |
| ROI confidence | >= 0.75 | Reject frame and request recapture |
| Glare contamination | <= 8% ROI pixels | Lighting guidance + reattempt |
| Motion artifact score | <= 0.20 | Recapture with stabilization guidance |
| Exposure clipping | <= 3% clipped channel area | Auto exposure adjust and retake |
Capture protocol quantitative controls
Figure: Capture and ergonomics flow
mermaid
flowchart LR
Guide[Guided framing] --> Hold[Stability hold]
Hold --> QC1[Focus/exposure checks]
QC1 -->|pass| Bundle[Frame bundle accepted]
QC1 -->|fail| Retry[Recapture guidance]Protocol steps from framing to accepted frame bundle.
Capture reliability is framed as a constrained measurement protocol that must survive unconstrained user environments. The design objective is not perfect optical control but reproducible minimum viable signal integrity under practical conditions. This requires instructive UI, adaptive feedback, and deterministic rejection criteria. In editorial terms, the chapter now clarifies that user behavior is an active component of the sensing system: guidance quality, prompt timing, and interaction sequencing can materially affect feature quality and downstream label stability.
Ergonomics are treated as quantitative variables. Distance to camera, head pose variance, blink frequency, and hand tremor each influence usable frame yield. By instrumenting these factors, the product can distinguish recoverable acquisition issues from non-recoverable contexts that require abstain. This distinction has practical impact on support burden and user trust. A system that repeatedly requests recapture without diagnosing cause appears unreliable; a system that explains specific capture constraints and routes decisively improves adherence and perceived reliability.
The chapter further clarifies device heterogeneity strategy. Rather than trying to normalize all pipeline differences out of existence, the program uses a hybrid approach: deterministic preprocessing to reduce variance, capability gating to exclude high-risk devices, and stratified validation to quantify remaining differences. This approach is more defensible than blanket claims because it produces explicit evidence about where the system performs reliably and where additional controls are required. In practice, this supports staged compatibility expansion with measurable risk management.
Lighting context is a recurring challenge and is handled through both protocol and policy. Protocol controls exposure and glare; policy controls interpretation under persistent adverse conditions. The editorial expansion emphasizes that lighting guidance is not merely UX polish. It is a safety-critical component that prevents false certainty. Capture conditions that repeatedly violate glare or clipping limits must route to abstain with clear follow-up direction. This design choice protects users from unstable outputs and keeps system behavior aligned with conservative clinical intent.
Capture engineering should be documented with explicit tolerance budgets for each instability source: illumination variation, focus drift, motion blur, gaze deviation, and occlusion. A tolerance-budget approach helps teams reason about compounding error. For example, a marginally acceptable exposure condition may become unacceptable when combined with motion and glare. Without budget thinking, controls are often tuned in isolation and fail under real-world interaction. This chapter now encourages joint-condition testing and composite QC criteria so protocol resilience is evaluated under realistic capture combinations rather than idealized single-variable scenarios.
Ergonomic protocol design is also expanded as a fairness and throughput issue. Users with tremor, older users, and users in constrained environments may require different prompt pacing and stabilization guidance. If the protocol assumes narrow interaction behavior, abstain rates can cluster inequitably across cohorts. This chapter recommends adaptive guidance windows, structured retry sequencing, and explicit device posture prompts to reduce avoidable acquisition failure. Such measures improve inclusivity while protecting analytical integrity, reinforcing the thesis that capture UX is part of the measurement system itself.
This chapter is expanded as a deeper methodological narrative around capture physics and ergonomic protocol resilience. The thesis assumes that durable clinical utility emerges only when signal-integrity constraints under uncontrolled smartphone environments is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how tolerance-budget testing, adaptive guidance, and cohort-aware capture ergonomics should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of compounded acquisition instability masked by single-variable tuning. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on joint-condition robustness evidence across lighting, motion, and device cohorts. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Better capture ergonomics reduces frustrating retries and prevents unsafe outputs from unstable scans is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
Frames captured outside protocol constraints must not be used for clinical signal estimation.
Acceptance criteria
Key takeaway
Protocol design, ergonomic guidance, and device gating jointly determine usable signal quality.
Open questions
Chapter 06
Specifies the deterministic QC state machine and preprocessing standardization required before model inference.
Why this chapter exists
Reader question: How do QC and preprocessing prevent unreliable outputs from reaching users?
Most field failures appear as confidence problems but originate in input quality and transformation drift.
Estimated reading time: 9 min
QC is the first formal safety barrier. No model output should be computed until QC verifies that imaging conditions meet minimum validity requirements. This reduces false confidence and constrains model exposure to adversarial or low-signal conditions. In a thesis-grade design, QC thresholds are explicit, testable, and auditable.
Preprocessing standardization minimizes cross-device instability by normalizing resolution, color statistics, temporal sampling, and ROI geometry. The objective is not to erase device differences entirely, but to reduce non-biological variance so model uncertainty reflects biological ambiguity rather than pipeline noise.
QC and preprocessing sequence
Safety doctrine
Abstain is not an error path. It is a designed safety outcome when evidence quality is insufficient for trustworthy inference.
Quantitative anchor
Decision = argmax{Pass, Reacquire, Abstain} under hard safety constraintsThe decision state is selected under deterministic constraints, not purely model confidence.
| State | Trigger condition | User-facing outcome |
|---|---|---|
| Pass | All hard thresholds satisfied | Continue to model stage and show output |
| Reacquire | Recoverable quality failure | Immediate recapture workflow |
| Abstain | Persistent low certainty or non-recoverable condition | No result; confirmatory-care guidance |
| Escalate | High-risk pattern with sufficient certainty | Priority escalation guidance |
QC decision state machine
Figure: QC state machine
mermaid
stateDiagram-v2
[*] --> Capture
Capture --> Pass: quality_ok
Capture --> Reacquire: recoverable_fail
Capture --> Abstain: persistent_low_certainty
Reacquire --> Capture
Pass --> [*]
Abstain --> [*]Decision transitions among pass, reacquire, and abstain outcomes.
Quality control is positioned as the principal boundary between acquisition variability and inference confidence. The expanded prose clarifies that QC thresholds should be empirically tuned using held-out validation data and revisited under post-market drift, not set once and forgotten. Because QC impacts both abstain rate and output reliability, threshold governance is a balancing problem: overly permissive thresholds inflate unsafe outputs, while overly strict thresholds reduce utility through excessive withholding. This chapter frames threshold policy as a measurable operating point, not a static constant.
Preprocessing is treated as a contract layer between capture and model. Any untracked change in color normalization, temporal sampling, or ROI transformation can invalidate prior model calibration. Therefore preprocessing configuration must be versioned and change-controlled with the same rigor as model weights. Editorially, this section now makes explicit that many perceived model regressions are actually upstream preprocessing regressions. Separating these concerns improves troubleshooting speed and reduces unnecessary model retraining triggered by pipeline drift.
The state machine model is expanded to distinguish user-recoverable failures from system-limited failures. Recoverable failures should produce concise corrective instructions and immediate recapture attempts. System-limited failures should terminate with abstain and clear escalation options. This distinction reduces repeated ineffective capture loops and supports better user trust. It also improves analytics, because reacquire-heavy sessions and abstain-heavy sessions imply different remediation paths at product and support levels.
A key editorial addition is observability requirements for QC behavior. The program should monitor per-device and per-context QC failure distributions, not only final output metrics. If a new OS release causes exposure failures to spike in a single device family, the system should detect and mitigate before clinical performance metrics visibly degrade. By placing QC telemetry in the research narrative, this chapter links algorithmic safety directly to real-time operations, reinforcing that preprocessing and QC are living controls.
QC policy should be modeled as a tunable operating frontier rather than a binary pass/fail ideology. Teams should publish target bands for pass rate, reacquire rate, abstain rate, and downstream reliability, then evaluate threshold candidates against this multi-objective profile. This avoids over-optimization of single metrics and enables transparent trade-off decisions. The chapter now emphasizes that QC thresholds are policy decisions informed by data, not purely technical constants. This framing improves cross-functional alignment because clinical and product owners can evaluate policy consequences before release.
Preprocessing governance is further strengthened by requiring transformation-level auditability. Each transformation stage should be reproducible and attributable in logs: color correction mode, ROI crop strategy, temporal smoothing profile, and normalization version. When post-market anomalies appear, teams can then isolate whether variance originated in input conditions, preprocessing, or inference. Without this granularity, root-cause analysis becomes speculative and correction cycles slow. This chapter therefore treats preprocessing transparency as an operational accelerant for safety and reliability maintenance.
This chapter is expanded as a deeper methodological narrative around quality-gate policy engineering and preprocessing traceability. The thesis assumes that durable clinical utility emerges only when operating-frontier optimization between reliability and abstain burden is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how versioned transformation contracts with transformation-level auditability should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of threshold drift and opaque preprocessing regressions. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on policy-level telemetry linking QC decisions to downstream outcome quality. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Robust QC and preprocessing keep users from receiving confident-looking results that should have been withheld is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
Model inference without QC pass is prohibited in all release modes.
Acceptance criteria
Key takeaway
QC thresholds and preprocessing versions are policy-governed controls, not static technical constants.
Open questions
Chapter 07
Describes a layered inference architecture that combines ensemble modeling with deterministic rules and calibrated uncertainty.
Why this chapter exists
Reader question: How does the model stack decide when to output versus abstain?
Raw model confidence can be unsafe unless constrained by calibrated uncertainty and deterministic policy checks.
Estimated reading time: 10 min
A single-model architecture is insufficient for this problem class due to device heterogeneity and context variability. The adopted strategy uses endpoint ensembles and a deterministic rules arbiter to reduce brittle behavior. The arbiter is intentionally conservative: contradictory or low-certainty outputs route to abstain rather than optimistic interpretation.
Uncertainty calibration is treated as a release-critical component. Confidence bands are not cosmetic metadata; they are gating signals that determine whether an output is actionable, advisory, or withheld. Severity mapping is only allowed when confidence exceeds minimum calibrated floors, preventing false urgency from unstable estimates.
Arbiter responsibilities
Quantitative anchor
Final Score = Arbiter(Ensemble Scores, Rule Constraints, Uncertainty Calibration)Arbiter output is policy-constrained, not merely probabilistic.
| Layer | Function | Safety guardrail |
|---|---|---|
| Feature backbone | Extract temporal/spatial ocular features | Version-locked preprocessing |
| Endpoint ensemble | Generate endpoint-specific probabilities | Cross-model consistency checks |
| Rules arbiter | Apply deterministic safety constraints | Blocks contradictory unsafe outputs |
| Uncertainty module | Calibrated confidence scoring | Triggers abstain when below threshold |
| Severity mapper | Map to urgency grade | Requires minimum confidence floor |
Model stack and arbitration contract
Figure: Rules + ML arbiter
mermaid
flowchart LR
Features --> EnsembleA[Model A]
Features --> EnsembleB[Model B]
Features --> EnsembleC[Model C]
EnsembleA --> Arbiter
EnsembleB --> Arbiter
EnsembleC --> Arbiter
Rules[Safety rules] --> Arbiter
Arbiter --> Decision[Label + confidence OR abstain]Parallel model outputs reconciled by deterministic safety rules.
The ML architecture is expanded here as a hierarchy of obligations rather than a collection of models. Endpoint ensembles must produce stable probability surfaces, but those probabilities alone do not authorize output. The arbiter enforces deterministic safety logic across model disagreement, uncertainty calibration, and policy constraints. This distinction is critical in medical software, where high raw model confidence can still be unsafe if generated from degraded input conditions or out-of-distribution context. The chapter therefore positions arbitration as a governance layer over probabilistic inference.
Calibration quality is elevated to release-critical status. Confidence bands must reflect empirical reliability, not cosmetic ranking. Poorly calibrated confidence creates dangerous UI semantics, because users and clinicians may interpret high-confidence labels as high-validity labels even when failure rates remain unacceptable in certain cohorts. The editorial pass emphasizes per-stratum calibration review and periodic recalibration under drift surveillance. Confidence is treated as an evidentiary claim that must be continuously defended with fresh data.
Trade-off management is made explicit: improving sensitivity through lower thresholds can increase false positives and escalation load; raising certainty thresholds can suppress risky outputs but increase abstain frequency. The system must optimize these trade-offs against intended-use priorities and operational capacity. This chapter adds language to ensure threshold changes are discussed as multi-stakeholder decisions involving clinical risk appetite, support readiness, and regulatory implications rather than isolated model-team tuning choices.
Update governance for model and rule bundles is also expanded. A model improvement that changes feature salience or class calibration may require corresponding arbiter updates and new user-facing explanations. Decoupled updates can create latent inconsistencies where policy assumptions no longer match model behavior. By explicitly documenting co-versioning expectations and regression burdens, this chapter reduces the risk of silent misalignment between ML output behavior and safety policy logic in production.
A deeper arbitration treatment requires explicit disagreement doctrine for ensemble outputs. When endpoint models diverge materially, the system should not silently average confidence. Instead, it should trigger rule-level conflict handling that evaluates uncertainty calibration, QC confidence context, and boundary constraints before rendering output. This prevents false stability from numerical aggregation and aligns result behavior with safety intent. The chapter now recommends logging disagreement classes as first-class telemetry, enabling targeted refinement of model and rule interactions where conflicts recur.
Model governance is also expanded around lifecycle comparability. New model versions should be evaluated not only for global metric gains but for behavioral continuity across high-risk cohorts and decision thresholds. A model that improves average AUC but worsens calibration in critical strata may be clinically inferior for intended use. This chapter therefore advocates release criteria that combine discrimination, calibration, abstain impact, and subgroup stability. Such multi-axis evaluation keeps optimization aligned with safe clinical utility rather than leaderboard-style metric improvement.
This chapter is expanded as a deeper methodological narrative around ensemble modeling, arbitration logic, and calibrated uncertainty. The thesis assumes that durable clinical utility emerges only when disagreement-aware inference governance with confidence calibration controls is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how co-versioned model-rule release discipline and conflict telemetry should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of numerical confidence that is not aligned with real-world reliability. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on multi-axis release criteria across discrimination, calibration, and subgroup stability. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Users benefit when uncertain or conflicting model states are handled transparently rather than averaged into false certainty is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
Any endpoint without calibrated uncertainty and arbiter constraints is non-deployable.
Acceptance criteria
Key takeaway
Arbitration is the safety governor over ensemble predictions, conflicts, and boundary conditions.
Open questions
Chapter 08
Defines data acquisition, labeling windows, stratification, and dataset governance required for defensible model development.
Why this chapter exists
Reader question: Is the dataset built to support fair and defensible claims?
Data distribution and label integrity define practical claim limits more than architecture alone.
Estimated reading time: 9 min
Data strategy is designed around generalization risk. Enrollment and evaluation are stratified by site, device family, and demographic variables so that measured performance reflects real deployment heterogeneity. Without this, reported metrics can overstate practical utility by conflating homogeneous training conditions with field conditions.
Label integrity requires explicit timing windows and reconciliation logic. For ocular biomarkers, reference labels can drift if collection windows are ambiguous; therefore protocol-level constraints define maximum allowed time deltas between capture and reference measurements. Exclusion rules are pre-specified and audited rather than post hoc.
Dataset governance requirements
Quantitative anchor
n_proportion ~= z^2 p(1-p) / w^2 ; n_error ~= (z*sigma / w)^2Program-level sample-size anchors used to plan confidence precision for key endpoints.
| Dimension | Required control | Audit evidence |
|---|---|---|
| Site stratification | Multi-site enrollment with holdout sites | Site-wise performance report |
| Device stratification | Family-level holdout by camera stack | Device-family confusion matrix |
| Label windows | Predefined timing windows per biomarker | Label timestamp reconciliation logs |
| Exclusion criteria | Protocol-defined quality exclusions | Exclusion reason distribution |
| Synthetic stress suite | Illumination/glare/motion/compression perturbations | Stress test regression report |
Dataset governance controls
Figure: Dataset and labeling pipeline
mermaid
flowchart LR
Capture --> Label[Reference label linkage]
Label --> QC[Data QA]
QC --> Split[Site/device holdout split]
Split --> Train[Training]
Split --> Eval[Locked evaluation]Data governance from acquisition through locked analysis sets.
The data chapter now articulates a stronger principle: dataset design is clinical design. Enrollment criteria, capture conditions, and label windows directly shape what the model can claim. If these design choices underrepresent certain devices or populations, the resulting model may appear globally strong while failing locally where care access needs are highest. The thesis therefore prioritizes stratified evidence plans that surface distribution weaknesses early and force remediation before outward-facing claim expansion.
Label governance is expanded to include temporal integrity and provenance validation. For biomarkers with dynamic behavior, even modest timestamp mismatch between capture and reference can degrade validity of supervision. The editorial pass clarifies that label alignment is not a data-cleaning afterthought; it is a first-order design parameter that should be monitored continuously during collection. Explicitly documenting label provenance enables reproducibility and makes later disagreement analysis tractable.
Synthetic perturbation is positioned as a supplement, not a substitute, for real-world diversity. Perturbation suites should challenge robustness claims under controlled variants (illumination, glare, blur, compression), but final deployability must remain anchored to prospective real-world evidence. This chapter adds operational guidance on how synthetic tests should be interpreted: as stress diagnostics for model fragility, not as standalone proof of field readiness. That distinction helps prevent overconfidence from laboratory-like stress benchmarks.
Finally, this section makes explicit that data governance quality determines change velocity. Teams with high-trust dataset lineage and stratification controls can evaluate updates faster because evidence queries are answerable. Teams lacking these controls slow down under review pressure. By embedding governance rigor into thesis documentation, NoDraw positions future iteration speed as a product of evidence infrastructure quality, not merely modeling talent or compute resources.
Data acquisition planning should treat representation targets as design inputs with explicit acceptance gates. Minimum counts by device tier, demographic cohort, and environment class should be set before collection, then reviewed continuously to prevent silent skew. Reactive balancing at the end of a study is usually more expensive and less effective than prospective allocation. This chapter now promotes quota-aware enrollment instrumentation and live dashboarding so collection teams can correct imbalance while studies are ongoing, reducing downstream fairness and generalization risk.
Label quality controls are expanded beyond inter-rater agreement to include reference process integrity: timestamp windows, specimen handling assumptions where applicable, measurement device lineage, and missing-data treatment policy. These controls matter because label noise in medical targets can look like model weakness or subgroup instability, obscuring true failure modes. By making label QA explicit, the chapter improves interpretability of validation outcomes and supports more defensible claim decisions when reviewers probe disagreement sources.
This chapter is expanded as a deeper methodological narrative around dataset governance, labeling integrity, and representational validity. The thesis assumes that durable clinical utility emerges only when prospective stratified data design as a determinant of claim quality is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how quota-aware collection, lineage controls, and temporal label alignment checks should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of label noise and representation skew hidden behind global metrics. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on data-quality controls that support fast, defensible update evaluation. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. High-integrity data practices improve fairness and reduce the chance of uneven quality across populations is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
Metrics from non-stratified or leakage-prone datasets cannot be used for outward-facing claim support.
Acceptance criteria
Key takeaway
Dataset governance must be stratified, time-aligned, and auditable to support trustworthy deployment.
Open questions
Chapter 09
Presents the phased validation framework from feasibility through post-market surveillance with explicit go/no-go thresholds.
Why this chapter exists
Reader question: What trial evidence is required for safe release-level claims?
Clinical utility depends on phase-correct evidence and transparent reporting, including abstain behavior.
Estimated reading time: 11 min
Validation is separated into feasibility, analytical validation, clinical performance, and post-market stability. Each phase has independent objectives and release gates. This prevents premature promotion of promising but underpowered findings and forces explicit evidence progression.
A locked statistical analysis plan is required before endpoint computation. This includes predefined metrics, confidence interval methodology, subgroup gates, and handling of abstain outcomes. The intent is to eliminate retrospective threshold tuning that can inflate apparent performance.
Go/no-go criteria logic
Quantitative anchor
Phase Advance = f(Primary Endpoint Pass, Safety Pass, Subgroup Pass, Governance Pass)All gate domains must pass for progression.
| Phase | Objective | Primary endpoint | Go/No-Go gate |
|---|---|---|---|
| Feasibility | Protocol and capture reliability | QC pass rate and acquisition success | Pass-rate threshold met |
| Analytical validation | Agreement vs references | Error metrics and calibration | Predefined accuracy gate met |
| Clinical performance | Decision utility in intended use | Sensitivity/specificity and safety outcomes | Clinical utility and safety gate met |
| Post-market | Drift and safety surveillance | Performance stability over updates | No critical drift without mitigation |
Clinical trial framework by phase
Figure: Validation lifecycle
mermaid
flowchart LR
F[Feasibility] --> A[Analytical validation]
A --> C[Clinical performance]
C --> PMS[Post-market surveillance]
PMS --> Update[Controlled model updates]Feasibility through post-market monitoring with explicit gates.
Validation design is expanded to emphasize phase integrity. Feasibility, analytical validation, and clinical performance serve distinct purposes and should not be collapsed into a single metric narrative. Feasibility validates protocol operability, analytical validation quantifies agreement behavior, and clinical performance evaluates decision utility under intended use. Mixing these objectives can produce superficially positive results that fail under deployment realities. The chapter now enforces phase-specific question framing to preserve interpretive clarity.
The editorial pass also elevates abstain outcomes in trial analysis. In safety-gated systems, abstain is a key endpoint because it mediates risk transfer from model to follow-up pathway. Trials that ignore abstain rates can overstate practical utility by focusing only on successful outputs. This chapter therefore treats abstain as a controlled operating characteristic that must be reported by cohort, device family, and scenario. Such reporting supports transparent trade-off decisions and better operational planning.
Protocol governance is expanded to include decision accountability. Predefined go/no-go criteria are necessary but insufficient unless owners, review cadence, and escalation authority are explicit. Ambiguous ownership often delays corrective action when a threshold fails. The chapter now reinforces that trial governance should include decision roles and documented rationale for any exceptions. This practice strengthens auditability and reduces the likelihood of undocumented threshold relaxation under schedule pressure.
Reporting discipline is explicitly aligned to modern AI reporting guidance. This includes transparent handling of missing data, subgroup performance, confidence intervals, and protocol deviations. By integrating STARD-AI and trial extension principles into chapter prose, the research page better supports external technical review and reduces ambiguity around what constitutes acceptable evidence sufficiency for claims in a rapidly evolving SaMD landscape.
Trial architecture should explicitly connect endpoint metrics to care-path decisions. Sensitivity, specificity, and calibration are necessary but incomplete unless tied to action consequences such as escalation burden, missed-risk exposure, and recapture workload. This chapter now frames validation as a decision-performance exercise, not only a classification exercise. By quantifying downstream operational impact, the evidence package becomes more useful for real deployment planning and more transparent for clinical partners evaluating practical value.
Sample-size planning is also expanded to require per-stratum confidence goals rather than one aggregate confidence interval target. Aggregate adequacy can hide subgroup fragility, especially in heterogeneous device ecosystems. The chapter recommends explicit precision targets for major cohorts and holdout strategies by site and device family so external validity is tested under realistic generalization conditions. This approach increases study complexity but reduces post-launch uncertainty and strengthens claim defensibility under regulatory and clinical review.
This chapter is expanded as a deeper methodological narrative around phase-structured validation and decision-performance evidence. The thesis assumes that durable clinical utility emerges only when distinction between feasibility, analytical validity, and clinical performance is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how stratum-specific sample planning, abstain reporting, and governance checkpoints should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of aggregate success narratives that hide subgroup fragility. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on protocol transparency with action-linked endpoint interpretation. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Clear trial evidence helps users and partners trust that outputs map to safe, practical next-step guidance is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
No phase may be skipped or merged when evidence gates are unmet.
Acceptance criteria
Key takeaway
Validation must tie metrics to care-path consequences, not only model discrimination scores.
Open questions
Chapter 10
Defines architecture boundaries between on-device inference, governance services, release management, and post-market monitoring.
Why this chapter exists
Reader question: How does NoDraw keep reliability stable as software and models change?
Post-release drift and incident response quality determine long-term clinical trust.
Estimated reading time: 9 min
The software architecture is intentionally split between a deterministic on-device inference plane and a governed update/monitoring plane. On-device execution preserves responsiveness and privacy posture, while cloud governance coordinates version control, telemetry aggregation, and controlled updates.
Operational safety requires traceability at each decision point: acquisition outcome, QC state, model version, arbiter result, and escalation route. Logs must be structured for both incident analysis and longitudinal drift tracking. Without this observability, no post-market claim can remain defensible.
Operational control domains
Quantitative anchor
Operational Integrity = Traceability + Controlled Change + Security Hygiene + Rollback ReadinessOperations quality is assessed as a systems property, not a single metric.
| Control area | Requirement | Monitoring mechanism |
|---|---|---|
| Release control | Versioned model + rule bundles | Signed release manifest and rollback path |
| Drift monitoring | Endpoint drift triggers | Population and device drift dashboard |
| Incident response | Defined severity classes | On-call playbook + post-incident review |
| Audit logging | Traceable inference and QC decisions | Immutable event stream retention policy |
Software and operations control matrix
Figure: Software and operations stack
On-device inference plane, optional cloud governance plane, and operational telemetry loop.
Software operations are expanded as a reliability economy problem: every release decision trades velocity against uncertainty, and only instrumentation can make that trade explicit. The chapter now emphasizes runtime observability as a clinical safety tool, not just an engineering convenience. Without granular telemetry on QC states, abstain patterns, and endpoint drift, post-market claims become speculative. Strong instrumentation turns operational noise into actionable evidence and supports faster, safer iteration cycles.
The updated prose clarifies model lifecycle controls under a controlled-change doctrine. Update proposals should declare intended impact, affected endpoints, required validation deltas, and rollback triggers before release. This precommitment reduces retrospective justification and aligns update behavior with regulatory expectations. In practical terms, it also improves cross-team coordination by making validation burden predictable for quality, clinical, and operations stakeholders.
Incident response is framed as an extension of evidence governance. When incidents occur, the objective is not only remediation but learning-system improvement: identify root cause class, update controls, and adjust monitoring thresholds where needed. The chapter now describes incident handling as a closed-loop process linking software telemetry, support narratives, and risk register updates. This integration prevents recurring failure modes from being treated as isolated support tickets.
Operational privacy and security controls are explicitly connected to clinical trust. Users will not separate inference quality from data stewardship quality; any perceived security weakness degrades clinical confidence. The editorial pass therefore treats cybersecurity and privacy posture as part of product reliability messaging and release readiness. Secure logging, data minimization, and governed retention are discussed as enabling conditions for sustained evidence collection, not as compliance checkboxes detached from product utility.
Operational architecture should be documented as a safety-relevant dataflow: capture events, QC outcomes, arbitration decisions, user messaging, and escalation actions need end-to-end traceability. When these traces are fragmented, teams cannot reliably explain field behavior or prove control effectiveness during audits. This chapter now recommends common event schemas across app, analytics, and risk systems so evidence can be joined without manual reconstruction. Structured telemetry becomes the backbone for both rapid incident response and long-horizon drift analysis.
Release governance is further strengthened by staged exposure controls and decision checkpoints tied to leading indicators. Canary cohorts, device-family guardrails, and automated rollback triggers should be defined before rollout starts. This precommitment reduces subjective override under pressure and protects users from broad exposure to uncertain changes. The chapter positions release orchestration as a clinical safety protocol implemented through software operations, not merely a DevOps optimization pattern.
This chapter is expanded as a deeper methodological narrative around runtime reliability, controlled updates, and incident learning loops. The thesis assumes that durable clinical utility emerges only when safety-relevant telemetry architecture across capture, inference, and escalation states is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how release orchestration with staged exposure and predefined rollback triggers should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of operational blind spots that delay detection of harmful drift. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on joined evidence streams connecting software events to quality and risk artifacts. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Operational rigor protects users from silent regressions and shortens time-to-correction when issues emerge is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
Any model update without predefined validation scope is blocked from release.
Acceptance criteria
Key takeaway
Operational telemetry, staged rollout, and rollback discipline are core clinical safety mechanisms.
Open questions
Chapter 11
Treats interface language, interaction constraints, and accessibility as core clinical safety controls.
Why this chapter exists
Reader question: Can users interpret outputs correctly under real-world constraints?
Communication failures can cause unsafe action even when inference quality is strong.
Estimated reading time: 8 min
In this program, UX is not a cosmetic layer. It is a safety-critical channel that determines whether users capture usable signals, interpret outputs correctly, and follow escalation guidance. Consequently, wording, interaction sequencing, and error states must be validated as rigorously as inference modules.
Accessibility has direct risk implications: if a user cannot read, navigate, or understand boundary statements, the safety model fails regardless of model quality. WCAG-aligned hierarchy, keyboard support, contrast, and assistive semantics are therefore part of release acceptance criteria.
Critical UX safety controls
Quantitative anchor
Interpretation Safety = Comprehension x Accessibility x ActionabilityIf any factor approaches zero, decision-support safety collapses.
| Risk | UX control | Validation evidence |
|---|---|---|
| Misinterpretation of result | Persistent boundary microcopy | Comprehension test in usability study |
| Ignoring low quality warning | Hard stop before result rendering | Task success in critical-path test |
| Accessibility barriers | WCAG 2.2 AA semantics and contrast | Screen-reader and keyboard audit |
| Escalation confusion | Severity + time-to-escalation copy | Scenario-based user testing |
Critical UX safety controls
Figure: UX safety loop
mermaid
flowchart LR
Prompt[Guided prompt] --> Check[Quality check]
Check --> Output[Result card]
Output --> Boundary[Boundary language]
Boundary --> Escalate[Escalation guidance]How wording, gating, and escalation messaging reduce misuse risk.
This chapter now frames interface design as an interpretive safety system. Inference quality has limited value if users misread urgency, misunderstand uncertainty, or fail to follow escalation guidance. The editorial expansion therefore emphasizes message sequencing and cognitive load management: critical meaning must be visible at the decision moment, not buried in legal pages or secondary screens. This principle is especially important in mobile contexts where attention and reading depth are limited.
Accessibility is expanded beyond compliance language into practical risk control. Low contrast, poor focus management, or inaccessible tables can create silent inequities where certain users receive less understandable safety information. In a thesis-grade system, these are not cosmetic defects; they are potential clinical communication failures. The chapter links WCAG conformance to measurable comprehension and task success outcomes, reinforcing that accessible design improves both fairness and overall system reliability.
Human factors validation is also reframed as ongoing, not one-time. As model outputs, boundary text, and escalation pathways evolve, usability evidence must evolve accordingly. A static usability report can become stale after meaningful product changes. The editorial pass therefore calls for cadence-based revalidation of critical tasks and language comprehension. This aligns with the broader change-control doctrine and ensures that communication safety remains synchronized with technical updates.
The chapter further clarifies the role of plain language in technical-first documentation. Technical-first does not require opaque wording at user touchpoints. Instead, technical rigor should govern internal logic while user-facing terms remain concise and actionable. This distinction helps preserve scientific integrity without sacrificing usability. In practical deployment, clear language reduces support escalation noise, improves adherence to recapture guidance, and decreases unsafe self-interpretation of uncertain outputs.
The UX thesis is expanded around interpretation reliability. A technically correct output can still fail clinically if users misunderstand urgency, confidence, or next steps. To reduce this risk, the interface should present a structured meaning stack: what was detected, how certain the system is, what action is recommended now, and when to seek confirmatory care. This chapter emphasizes consistent phrasing across screens and regions to avoid meaning drift. It also treats message order as a safety design choice, not a copywriting preference.
Accessibility depth is expanded to include cognitive and situational accessibility, not only visual conformance. Medical guidance may be read in stress conditions or low-attention contexts, so brevity, hierarchy, and redundancy become essential. The chapter recommends comprehension testing for critical outputs, clear focus states for keyboard use, and mobile table patterns that preserve legibility under narrow widths. These controls improve fairness and reduce the chance that vulnerable users receive less actionable safety information.
This chapter is expanded as a deeper methodological narrative around interpretive safety, usability assurance, and accessibility equity. The thesis assumes that durable clinical utility emerges only when message architecture that preserves urgency and uncertainty comprehension is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how critical-task validation, route-level copy consistency, and accessibility QA cycles should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of communication failures that convert technical correctness into unsafe user action. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on comprehension-linked usability evidence beyond baseline conformance checks. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Accessible and clear interfaces improve adherence, reduce confusion, and support safer decision-making for diverse users is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
If users cannot reliably interpret or act on outputs, the system is unsafe regardless of predictive accuracy.
Acceptance criteria
Key takeaway
Interpretive safety and accessibility are first-class risk controls, not design polish.
Open questions
Chapter 12
Operationalizes an ISO 14971-style risk model that binds hazards to controls, verification, and post-market monitoring.
Why this chapter exists
Reader question: How are hazards controlled, monitored, and re-evaluated over time?
A static risk register cannot keep pace with fast software and device ecosystem changes.
Estimated reading time: 9 min
Risk management is modeled as a continuous lifecycle loop rather than a pre-release checklist. Hazards are identified at technical, clinical, and operational layers, then linked to preventive controls, verification tests, and ongoing surveillance indicators. This structure ensures that safety claims remain supportable after launch.
For smartphone ocular diagnostics, prominent hazards include low-light misclassification, glare corruption, subgroup imbalance, overinterpretation, and drift after camera stack updates. Each risk has a designated owner and threshold for escalation. Residual risk decisions are explicit and revisited under post-market evidence.
Risk control cycle
Quantitative anchor
Residual Risk = Inherent Risk - Control Effectiveness + Drift ExposureResidual risk must remain within approved tolerance bands over time.
| Hazard | Type | Primary control | Residual posture |
|---|---|---|---|
| Low-light misclassification | Technical | Hard low-light gate + recapture | Managed with active monitoring |
| Glare-induced feature corruption | Technical | Glare detector and ROI masking | Managed with stress-suite coverage |
| Subgroup performance imbalance | Clinical | Subgroup gates and blocked release on failure | Managed with mandatory reporting |
| Model drift after OS updates | Operational | Drift alarms + staged rollout | Managed with rollback controls |
| Overclaim interpretation | Clinical/Comms | Prohibited claims policy + legal review | Managed with publishing guardrails |
Top risk register snapshot
Figure: Risk control chain
mermaid
flowchart TD
Hazard --> Cause
Cause --> Control[Preventive control]
Control --> Verify[Verification test]
Verify --> Residual[Residual risk decision]
Residual --> Monitor[PMS monitoring]Hazard identification through residual-risk acceptance.
Risk governance is expanded to emphasize causal specificity. Broad labels such as model drift or low-light failure are insufficient unless decomposed into actionable sub-causes with measurable controls. The chapter now encourages cause-level mapping: sensor clipping, ROI instability, calibration mismatch, policy misconfiguration, and communication breakdown should each have distinct controls and monitoring indicators. This granularity improves CAPA effectiveness and reduces recurrence of superficially similar but mechanistically different incidents.
Residual risk acceptance is framed as a dynamic governance decision with evidence expiry. A risk deemed acceptable under one device distribution or model version may become unacceptable after platform changes or population shifts. The editorial pass therefore adds language on reassessment triggers tied to drift signals, incident clusters, and major update classes. This makes risk posture adaptive and prevents outdated acceptance decisions from silently persisting in evolving operating environments.
The safety case now integrates communication risk more explicitly. Overclaim phrasing, ambiguous confidence labels, and inconsistent boundary text can convert technically correct outputs into unsafe decisions. This is treated as a first-class hazard category, with controls including vocabulary standardization, legal-clinical review loops, and route-level copy audits. By elevating communication hazards, the chapter aligns narrative governance with technical governance and closes a frequent gap in digital health programs.
Operationally, the chapter clarifies that risk monitoring should support forward indicators, not only lagging incident counts. Rising recapture rates in a specific cohort, increasing abstain concentration on certain device families, or sudden changes in escalation mix can signal pending reliability issues before severe incidents appear. Embedding these forward indicators in the safety case strengthens early intervention capacity and improves resilience under real-world drift conditions.
Safety-case strength depends on traceable causal logic: hazard, initiating condition, control, verification evidence, and residual risk rationale. This chapter extends that chain with monitoring triggers and corrective-action pathways so controls remain live after release. Without monitored control efficacy, risk files become static records that do not reflect operational truth. The thesis therefore treats risk management as a continuous loop where field evidence can confirm, challenge, or retire prior assumptions about hazard likelihood and severity.
A further refinement is integrating communication hazards into the same quantitative governance framework used for technical hazards. Ambiguous confidence labels, inconsistent boundary text, and over-assertive copy can increase misuse probability even when inference quality is stable. The chapter recommends measurable controls for communication risk: vocabulary checks, route-level copy audits, and user comprehension gates for critical statements. This closes a persistent gap between engineering safety culture and content publication practices in software-led diagnostics.
This chapter is expanded as a deeper methodological narrative around hazard-causal mapping and dynamic residual-risk governance. The thesis assumes that durable clinical utility emerges only when cause-specific control design with monitored efficacy and reassessment triggers is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how integration of technical, communication, and operational hazards in one safety case should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of stale risk acceptance decisions in fast-changing software ecosystems. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on field-informed CAPA loops that continuously update risk assumptions. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. A living safety case reduces the probability that known weaknesses recur in production user journeys is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
Risk acceptance is conditional and must be revalidated when model, device, or operating context materially changes.
Acceptance criteria
Key takeaway
Risk management is a living loop linking causal hazards, control efficacy, and field evidence.
Open questions
Chapter 13
Defines launch readiness and post-launch governance for a phone-only ocular SaMD operating in heterogeneous real-world conditions.
Why this chapter exists
Reader question: How does NoDraw scale safely after initial launch?
Controlled rollout and surveillance quality directly affect user safety and system credibility.
Estimated reading time: 8 min
Deployment is treated as a controlled clinical software rollout, not a pure app release. Readiness requires alignment across technical validation, regulatory artifacts, device compatibility governance, support operations, and incident response. This integrated launch model is mandatory to preserve safety behavior under real-world variability.
Post-market surveillance monitors drift, abstain rates, subgroup performance, and incident patterns. Operational decisions include rollout pacing, rollback activation, support burden balancing, and evidence refresh cadence. The system must sustain trust by proving that post-launch behavior remains within validated boundaries.
Launch gating workstreams
Quantitative anchor
Launch Readiness = min(Technical, Regulatory, Operational, Monitoring)The weakest readiness domain determines deployability.
| Workstream | Definition of ready | Owner |
|---|---|---|
| Device compatibility | Supported matrix approved and tested | Mobile engineering |
| Regulatory dossier | CEP, RMF, SLP, usability pack complete | Regulatory + quality |
| Clinical operations | Protocol monitoring and escalation workflows set | Clinical operations |
| Support readiness | Incident response and triage scripts complete | Customer operations |
Deployment readiness criteria
Figure: Deployment gate model
Readiness gates covering technical, clinical, regulatory, and operations handoff.
Deployment readiness is expanded as a cross-functional convergence event rather than an engineering milestone. Product, clinical, regulatory, quality, and support workstreams must align on the same release doctrine and evidence posture. Misalignment between these domains often produces post-launch instability even when model metrics appear acceptable. The chapter now frames launch as a systems readiness decision where the minimum maturity across domains determines practical safety and trust outcomes.
Post-market surveillance is positioned as thesis continuation, not maintenance overhead. Real-world usage generates new evidence about capture behavior, subgroup performance, and user interpretation that cannot be fully simulated pre-launch. The editorial pass emphasizes that this data should be fed back into chapter assumptions, threshold governance, and claim language revisions. In this model, the research page becomes a living record of how the product learns under operational reality.
The chapter also expands support operations role in evidence quality. Support interactions can reveal recurrent misunderstanding patterns, device-specific friction, or escalation confusion that formal metrics miss. Structured support telemetry should therefore be integrated with model and QC dashboards. This integration transforms support from a reactive function into an early-warning sensing layer for product safety and usability drift.
Rollout governance is clarified as a staged confidence-building process. Initial deployments should use constrained exposure, close monitoring intervals, and explicit rollback readiness. As evidence stabilizes across cohorts and device groups, exposure can expand. This staged posture aligns with both safety and operational efficiency: it limits blast radius during uncertainty while enabling controlled scale once reliability is demonstrated. The editorial additions make these rollout mechanics explicit rather than implied.
Deployment strategy is deepened with explicit market-entry guardrails: start with constrained regions and device sets where support readiness, clinical referral pathways, and monitoring infrastructure are strongest, then expand as evidence stabilizes. This reduces early systemic risk and allows operational learning to inform broader rollout. The chapter now frames scaling as conditional expansion, where each stage requires monitored success on safety, reliability, and interpretation metrics before the next stage unlocks.
Post-market surveillance is expanded into a structured learning program with predefined review cadence and action thresholds. Rather than collecting telemetry passively, teams should run periodic evidence reviews that compare observed behavior with premarket assumptions. Discrepancies should drive targeted protocol updates, threshold recalibration, or claim boundary adjustment. This approach keeps the public thesis synchronized with field reality and prevents stale assumptions from accumulating across rapid software and device ecosystem changes.
This chapter is expanded as a deeper methodological narrative around staged rollout governance and post-market evidence accumulation. The thesis assumes that durable clinical utility emerges only when conditional scale strategy tied to monitored safety and reliability indicators is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how cross-functional launch readiness with structured surveillance review cadence should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of broad release before support and monitoring maturity. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on post-market learning loops that recalibrate thresholds and claim posture. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Controlled rollout and active surveillance improve stability of the experience users receive after launch is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
If post-market indicators breach predefined limits, rollout must pause and corrective controls must be applied.
Acceptance criteria
Key takeaway
Scale is conditional on monitored safety, support readiness, and evidence stabilization.
Open questions
Chapter 14
Final governance chapter mapping each public-facing claim to required evidence, thresholds, and release decisions while listing prohibited overclaims.
Why this chapter exists
Reader question: How do published claims stay synchronized with the latest evidence?
Claim drift is one of the highest-impact trust and safety risks in digital diagnostics.
Estimated reading time: 8 min
Claim governance is the final safety layer between technical ambition and public communication. Every public statement is treated as a release artifact with mandatory evidence binding. This prevents narrative drift, overclaim risk, and misalignment between engineering outputs and external messaging.
The program distinguishes between thesis-level vision and release-level claim eligibility. Vision can be broad, but deployable claims require documented study type, sample size rationale, endpoint thresholds, subgroup checks, and residual risk position. Claims without this structure remain internal hypotheses.
Prohibited claims doctrine
The system must never claim direct cell counting from camera-only imagery, universal lab equivalence, or treatment-ready autonomy without confirmatory care.
Required claim evidence fields
Quantitative anchor
Claim Eligibility = Evidence Sufficiency AND Boundary Compliance AND Risk AcceptanceAll three conditions must hold for release-level communication.
| Claim | Evidence requirement | Pass threshold | Release decision |
|---|---|---|---|
| Early risk signal generation | Analytical + clinical performance evidence | Predefined endpoint gate achieved | Conditional release |
| Quality-gated safety behavior | QC state machine validation | No bypass path in test suite | Required for release |
| Device-generalized operation | Holdout device-family performance | No critical subgroup failure | Required for release |
| Confirmatory-care boundary | Comms and legal compliance audit | Boundary text present in all risk surfaces | Required for release |
Claim-to-evidence acceptance map
Figure: Claim-to-evidence trace graph
mermaid
flowchart LR
Claim --> Evidence
Evidence --> Dataset
Dataset --> Metrics
Metrics --> Threshold
Threshold --> ReleaseDecisionClaims route to datasets, metrics, and release thresholds.
The final chapter is expanded to treat claims as versioned clinical software outputs. A claim is not a static sentence; it is an executable contract linking intent, evidence, thresholds, and risk acceptance. When any linked component changes, claim validity must be reassessed. This perspective prevents stale claims from persisting after model updates or distribution shifts and aligns public communication with current system behavior.
The chapter adds stronger separation between visionary roadmap statements and deployable present-tense claims. Visionary statements can guide strategy but must be clearly identified as forward-looking. Deployable claims require completed evidence chains and active boundary controls. Mixing these categories creates legal and clinical ambiguity that can undermine trust. The editorial pass therefore encourages explicit labeling of claim maturity and systematic review at each release cycle.
Inline citation discipline is also expanded as a governance mechanism. By forcing claim-adjacent references, the page makes unsupported escalation visible during review. This reduces reliance on reviewer memory and improves reproducibility of editorial decisions. Citation-linked claims are easier to audit, easier to revise, and easier to retire when evidence changes. In this sense, bibliography quality directly affects policy quality.
The prohibited-claims appendix is framed as an active control surface, not legal boilerplate. It should be consulted during feature planning, copywriting, and launch review to prevent speculative statements from entering user-facing channels. Embedding this doctrine in the thesis route ensures that ambition remains bounded by evidence and safety policy. This preserves long-term credibility while allowing aggressive innovation inside governed experimental channels.
Claim governance is expanded into a publication-control workflow. Before any claim appears on product surfaces, it should pass structured checks for evidence sufficiency, wording accuracy, boundary presence, and citation integrity. This workflow prevents claim drift between technical documents and user-facing copy, especially when multiple teams contribute content. The chapter now recommends periodic claim reconciliation where active claims are compared against the latest study outputs and risk posture updates. Claims that no longer meet thresholds should be downgraded or withdrawn promptly.
The final editorial refinement is to treat claim communication as versioned software behavior. Just as models and rules are versioned, claim text and boundary language should carry version identifiers and review history. This makes it possible to audit which claims were active for a given release and why. It also accelerates incident review by tying communication state to technical state. By institutionalizing this discipline, the thesis preserves scientific ambition while maintaining durable trust through verifiable communication governance.
This chapter is expanded as a deeper methodological narrative around claim publication control and communication-version governance. The thesis assumes that durable clinical utility emerges only when evidence-bound claim lifecycle management with explicit maturity states is translated into reproducible operating behavior, rather than left as a conceptual claim. That translation requires explicit mechanism descriptions, controlled vocabulary, and measurable constraints that can survive real deployment noise. A major editorial objective in this pass is to make hidden assumptions visible so expert reviewers can challenge them before they propagate into release posture. The chapter therefore emphasizes not just what the system intends to do, but why the chosen framing is technically defensible under smartphone-only limits, heterogeneous devices, and variable field conditions. By making chapter intent inspectable at this level, the document moves closer to thesis-grade rigor and reduces interpretation ambiguity across engineering, clinical, and regulatory readers.
At execution level, the expanded prose details how pre-publication checks for wording, boundary, and citation integrity should be implemented as a controlled workflow instead of an ad hoc optimization effort. This includes defining preconditions, measurable outputs, failure states, and owner accountability for every critical transition. The chapter now treats process clarity as a safety property, because unclear operational boundaries usually manifest as delayed incident detection, inconsistent escalations, and policy drift over time. It also clarifies that quality outcomes must be interpreted through stratified telemetry rather than aggregate averages, especially in mobile ecosystems where device cohorts can behave differently under identical logic. These additions help teams reason about practical deployment consequences before release and ensure that chapter guidance is actionable in production, not merely persuasive in documentation.
From a risk perspective, this section further expands the treatment of communication drift between technical truth and public messaging. The goal is not to enumerate generic hazards, but to define causal pathways that can be monitored, mitigated, and re-evaluated as software and environment conditions evolve. The editorial pass stresses that conservative behavior must be designed into the system architecture, communication layer, and review process simultaneously. If any one of these control surfaces weakens, the safety profile can degrade even while nominal model metrics appear stable. To prevent that failure mode, the chapter now reinforces explicit boundary language, threshold governance discipline, and predefined corrective-action triggers. This style of writing is intentionally procedural: it allows reviewers to infer how teams should act when evidence becomes contradictory or when operating assumptions no longer hold in the field.
The final long-form paragraph in this chapter links local detail to global program credibility by focusing on versioned claim reconciliation aligned to latest study and risk outputs. A thesis-level artifact must show that chapter claims can be defended repeatedly across release cycles, not only at publication time. For this reason, the text now highlights versioning discipline, evidence refresh cadence, and cross-chapter consistency checks as mandatory controls. Strong claim governance ensures users encounter language that matches verified system behavior is used as the practical consequence lens: if this chapter is implemented well, users receive clearer and safer outcomes; if implemented poorly, uncertainty is obscured and risk is transferred silently to downstream care pathways. By adding this integration layer, the chapter becomes a decision instrument for technical leadership rather than a static reference section, and it aligns the page with long-horizon evidence governance expectations.
Boundary Statement
Claims that fail evidence sufficiency or boundary compliance must be removed from production communication.
Acceptance criteria
Key takeaway
Claims are versioned artifacts that require evidence sufficiency, boundary compliance, and risk acceptance.
Open questions
Numbered citations used inline throughout all chapters. Reference links are grouped by corpus type for technical verification and audit navigation.
Tambua Health, 2026. Primary internal technical source for architecture, governance, and validation structure.
Tambua Health, 2026. Program-level thesis framing, assumptions, and deployment rationale.
Tambua Health, 2026. Extracted method and gap inventory for phone-only ocular SaMD scope.
Tambua Health, 2026. Program structure reference for chapter ordering and evidence plan depth.
Tambua Health, 2026. Claim-to-evidence mapping schema for release and audit readiness.
Tambua Health, 2026. Risk taxonomy and control structure baseline for operational safety case.
IMDRF, 2017. Clinical evidence model for scientific validity, analytical validity, and clinical performance.
ISO, 2016. Medical device QMS framework.
ISO, 2019. Medical device risk management framework.
IEC, 2006+A1:2015. Software lifecycle process standard for medical device software.
IEC, 2015+A1:2020. Usability engineering for medical devices.
ISO, 2007/2020. Ophthalmic instrument safety context for light exposure.
IEC, 2006. Photobiological safety of lamps and lamp systems.
FDA, 2024. Predetermined change control framework for AI/ML device modifications.
FDA, 2023. Cybersecurity lifecycle expectations for medical devices.
FDA, 2023. Premarket documentation expectations for device software functions.
HHS, Current. US health information privacy baseline.
EU, Current. EU data protection and rights framework.
Google Android, Current. Hardware capability gating reference for phone segmentation.
BMJ, 2025. Reporting standards for diagnostic AI studies.
Nature Medicine, 2020. AI trial reporting extension for randomized studies.
Nature Medicine, 2020. AI protocol reporting extension for prospective trials.
PLOS ONE, 2016. Phone-based jaundice screening concept using scleral color analysis.
NIH/PMC, 2025. Smartphone pupillary response measurement feasibility and clinical context.
Internal sources are published with metadata and full content so internal citations resolve to meaningful evidence pages.
Primary internal technical manuscript covering architecture, safety logic, validation doctrine, and claim boundaries.
Owner: Tambua Health Research Team
Open full sourceExecutive framing document describing intended scope, posture, strategic assumptions, and deployment rationale.
Owner: Tambua Health Research Team
Open full sourceMethod extraction and gap inventory used to convert broad research language into actionable engineering evidence work.
Owner: Tambua Health Research Team
Open full sourceChapter-by-chapter structure and depth targets used to organize long-form thesis content and acceptance checkpoints.
Owner: Tambua Health Research Team
Open full sourceStructured claim-to-evidence matrix defining claim text, study expectations, thresholds, and pass/fail readiness gates.
Owner: Tambua Health Research Team
Open full sourceISO 14971-aligned risk register template covering hazards, harms, controls, verification evidence, and residual risk.
Owner: Tambua Health Research Team
Open full sourceReusable SAP template for endpoint definitions, sample-size logic, subgroup analysis, and reporting standards.
Owner: Tambua Health Biostatistics Team
Open full sourceClinical protocol template for inclusion criteria, endpoints, monitoring, and governance responsibilities.
Owner: Tambua Health Clinical Research Team
Open full sourceThis thesis is intentionally rigorous because the product is safety-critical. If you are ready to proceed, start a companion diagnostics pilot intake and follow confirmatory-care recommendations where indicated.